Over the summer, a new state-of-the-art AI image generator, Stable Diffusion was released. Unlike its competitors which remain largely paywalled, it was made freely downloadable, smashing open a piñata of hype, panic and potential. Influential researcher (and former Director of AI at Tesla) Andrej Karpathy described it as ‘a day of historic proportion for human creativity‘.
With investment dollars pouring in, including a $101m for Stability.AI, the company behind Stable Diffusion, the field of “Generative AI” has quickly become this seasons venture capital unicorn ranch and nothing will ever be the same again, again.


Stable And Diffused
I’ve been experimenting with Stable Diffusion since its release – see the numbered images in this post – and while contending with such intense buzz requires caution – also TLDR; I don’t think I’ve ever used a piece of code or software that has left such an intense impression so quickly.
Stable Diffusion doesn’t appear to be hugely more capable than its competitors MidJourney or Dall-E although the outputs it generates are generally more fascinating, especially in the terrain beyond style-transfer. Its primary advantage is that it’s downloadable and free to operate on your own PC, providing space to both fine-tune it’s process and to some extent reverse engineer its logic. As someone who spends a significant amount of time making and thinking about images – inputting my own images and drawings into Stable Diffusion has thrown up some knotty questions.

Before getting into these, the quickest shortcut through the hype might be just to try it for yourself and experience both its weirdness and limitations. There are many guides, tutorials and easy to use interfaces such as webui, which is perhaps the most active and stable-diffusion-ui, which is possibly marginally easier to install. It can be used directly online at huggingface or dozens of other hosted version that have sprung up, although tinkering with a local installation provides the most flexibility.
Generative Search
Sidestepping the tangled definitions of intelligence, we can at least recognise that such models are capable of extraordinary feats of translation, allowing us to skirt across vast dimensions of latent space and metaphorical image analysis that 150,000 hours of top grade GPU training time affords. We may not yet have sufficient metaphors to describe these interactions, landing somewhere between co-creation and augmented visual research made possible by ingesting 5.8 billion images. As a tool of self-evaluation it’s remarkably useful to be able to supply it images and essentially ask ‘what is this?‘ and then ‘what it would be like as something slightly, or significantly, or entirely different?’. It’s a process that feels conversational, and stranger still, one where the other party is adamantly attempting to convince you that images are not what you thought they were.
The term-of-art to describe the process of fine-tuning the inputs is known as ‘Prompt Engineering’, although we may quickly need a more expansive term, that is less suggestive of a short, written starting points and more considerate of different potential input methods. How we feed such models is now encompassing all forms digital media – see emerging techniques for speech2video or text-to-3D aka Dreamfusion. Naturally some are already using one AI to work out what to ask another.
In a talk around a decade ago, I remember the artist Mark Leckey comparing image search engines to alchemy, since they could, if used effectively, conjure images from our imagination into being. In the era of “Big Data”, search could be considered be a productive, creative act.


It was also an acknowledgement that, in a world where images are no longer scarce or hidden, how we work with them and what they mean might need to be fundamentally reconsidered. As with many technologies, there is a window between our first interactions initial it and it’s maturity. This same process feels like it’s happening with AI image generation, albeit slightly faster. I remember using Google Image Search not long after it was originally launched, it was both revelatory and yet also strangely limited. Before long it ‘got good’, and what once felt slightly unreliable, quickly cemented itself as an essential component of how we think about images.
Emad Mostaque, CEO of Stability.ai describes using his model as ‘generative search’ – perhaps he was also in attendance at Leckeys lecture. He also predicts bombastically that “image will be solved within a year“. Siri – set a reminder, 17th October, 2023. Hype train aside – it does seem likely that the underlying capacity of such technologies is going to keep growing in the near future. From the perspective of what they can already do, things are only going to get weirder.
Open Season
The crescendo of excitement surrounding Stable Diffusion is partly thanks to its public release. While the main competitor Midjourney currently has 3 million members on its discord, that’s primarily because chatting with a bot is the primary way to use use it. By decoupling the model from the service offering, Stability.AI has been propelled skyward by a community eager to to build things on top of the technology. This community is growing wildly fast and releasing a stream of visual tools and genre-bending proof-of-concepts, with new resources available almost daily.
Nowhere is this more evidence that the rapid-fire demoscene of interfacial experiments, such as the VR & 360 Demos by ScottieFox, and live AR demos by Stijn Spanhove and Sergie Galkin. Daniel Eckler has also compiled a fantastic thread. For a general state of play, a good place to start is reddit: r/StableDiffusion and r/sdforall or the discord. This outpouring of activity is the result to Stability.Ai’s gamble to embrace an an alternative business model, helpfully summarised by swyx’s “How Open Source is eating AI”.
The Rest Is Noise
It’s tempting humanise these tools, thinking of the model as somehow intuitive since its outputs can sometimes feel so unexpected, complex or perhaps even baffling. For now at least the very opposite is true, part of what makes it so interesting is that the latent space from which it pulls images is fully explorable – we can export an image for every step of the way or restart the process where we left off.
To such models, every image resembles a Monet painting or ‘A bottle of ranch testifying in court‘, to some extent – it’s just that most of the time it’s 0.000%. To this end we can consider essentially all images, generated or otherwise as a bundle of definitions within Stable Diffusions hyper-dimensional latent space. To generate an image is to chart a logical (or absurd) route through the model, sampling the states of confusion and intrigue along the way, jiggling images from 0.041% of this to 0.98% of that.
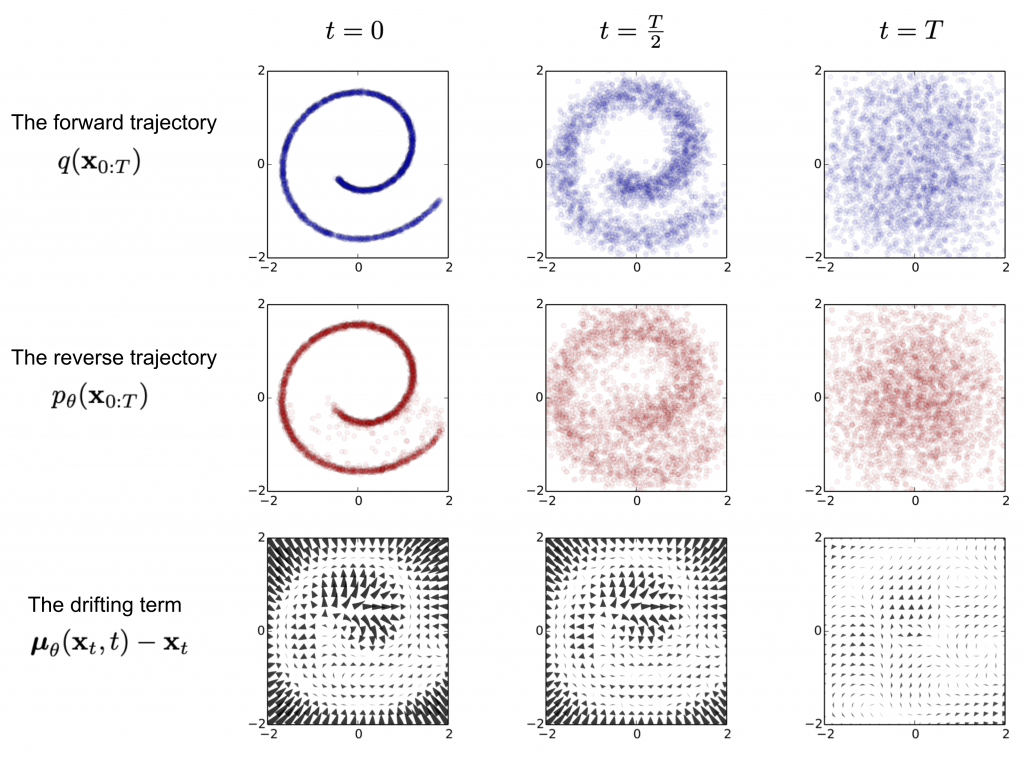
Curiously the underlying technical architectures of diffusion models, i.e Stable Diffusion, have their origins in thermodynamics. Authors on one of the early papers on the topic summarise it as: “The essential idea, inspired by non-equilibrium statistical physics, is to systematically and slowly destroy structure in a data distribution through an iterative forward diffusion process.”
It turns out to be deliriously effective to train a neural network by adding and removing noise from an image in tiny iterations. We might even think of Stable Diffusion as essentially hyper-specialised noise reduction repeated dozens of times over. Generally the individual gradual steps along this path are nearly imperceptible to the human eye – in aggregate however the model can travel on what appears to be a wild ride of imagination.
That doesn’t mean we can directly parse it’s reasoning. For instance the outputs can dramatically change form when it’s underling parameters, such as ‘de-noising’ are only marginally adjusted, from say 0.875 to 0.9 as if crossing a threshold beyond which the model can no longer contain itself.
Floating in Latent Space
Stable Diffusion works because it is trained on 5.8 billion images but it’s also appears fundamentally scarred by the process. It is common for images it generates to feature a hallucinated stock image watermark or ‘garbled Getty images’ banner. In her essay ‘The Spam of the Earth: Withdrawal from Representation’ Hito Steyl reminds us that we have inadvertently flooded actual deep space with spam, “Image spam is our message to the future.”. Now we’re filling our artificial brains with spam and stock image offcuts as well.

However these issues may be trivial to bigger concerns now that a model with such power is out-in-the-wild. Stability.ai claim that the images are digitally watermarked, there are safeguards against NSFW content and mandate some fairly hefty licence restrictions. However judging by some of the community outputs this is almost impossible to regulate and potentially laying the groundwork for even more complex challenges.
Benjamin Bratton & Blaise Aguera y Arcas, in their recent essay “The Model Is The Message: Why We Need New Language For Artificial Intelligence “ partially in response to Google Engineer Blake Lemoines claim that the LaMDA chatbot might be ‘sentient‘, define “Seven Problems With Synthetic Language At Platform Scale”. Two of these seven seem of immediate relevance to the release of Stable Diffusion – The Machine Majority Language Problem – what happens when the majority of language is spoken machine made? Then as a chaser – The Ouroboros Language Problem – what happens when the models are then trained on a corpus that was machine made?
Getty and Shutterstock have already banned AI generated images given the sudden ease of being able to make them and the training pool for the next generation models is probably now already polluted. As Bratton and Aguera y Arcas observe, given the forthcoming onslaught of AI content, more radical approaches may be necessary, such as tagging content which is explicitly ‘human made‘.

Although their focus is on language processing models, the underlying logic is not only directly transferable to image generation, but really all machine learning approaches to media – as they write “the sequence modeling at the heart of natural language processing is key to enabling generalist AI models that can flexibly do arbitrary tasks, even ones that are not themselves linguistic, from image synthesis to drug discovery to robotics”.
While of course Stable Diffusion is largely manipulated with text-based prompts, the deeper consideration here is that linguistic capacity is the likely foundation for computational systems that can learn or build models of the world with a comparable speed, flexibility or inventiveness that even small children might display when picking up grammar, syntax and vocabulary. When it comes to machine learning, metaphor isn’t a metaphor.
Stock Check
So the commercial viability of libraries of stock images, game textures (and in time footage, copy-right free music) is perhaps shaky, but more fundamentally, but so to is the very nature of the ‘stock’ image. It’s easy to forget such archives represent an industrialisation of visual communication, though the continuous production of generic images, vector graphics, symbols, logos and templates. What’s changing is that the ‘stock’ is no longer a store but likely to become a process – the fruits of which will be strange. Adaptive illustrations that A/B test themselves, hyper-personalisation, deep instability.
It is only within the last few years that architectural visualisation and product photography has really got anywhere close to a level of ‘true’ photo-realism which might reasonably confuse experienced professionals, mainly because achieving the right level of complexity and textural variation that we are subconsciously rely on is extremely tedious or expensive. At the very least we can imagine that a commercial rendering pipelines are going to start including AI if only to sprinkle some of this magic realism dust at various stages of the pipeline.

Stable Diffusion appears capable of generating a particular flavour of unreality. Given the right blend of inputs it will generate detail, form and lighting that reassure the human eye and appears to ‘know’ how to make something appear 3D or correctly textured while simultaneously making fundamental logical errors that we don’t immediately acknowledge. While machine vision may be able to police machine image production, human labelling may soon be a thing of the past.
What this means for digital professional is a more complicated question. It’s true that creative people who depend on a highly cultivated visual language may take a hit from unscrupulous actors if potential legal protections are fiddly to design or slow to be realised, but these may in time, also be easily addressable concerns to legislate for. To hold focus on the legal or economic side may gloss over the fundamental expansion and necessary reconstitution of what it means to be ‘an artist’ in the first place.
At a basic level, the premise that AI can independently make coherent art is essentially a boring category error, illustrating the somewhat reductive nature of conversations in mainstream and tech discourse, often based on the overestimation of the importance of ‘style’, as if visual art has remained static since Van Gogh chopped off his ear. While it may sound slightly obnoxious – it may also be literally true – that AI models and their creators might find a great advantage by somehow integrating lessons from art history and visual theory instead of presuming it can continue to be brute-forced a billion images 512px x 512px at a time.
Stabilisation (And Its Discontents)
This isn’t to make a value judgement about the different ways that people might use Stable Diffusion, quite the opposite, art is perhaps the primary process through which we as humans will build a cultural understanding of the computational structures that AI is revealing, and the wider the gamut of outputs, the better. As we shift from demo to tool it’s likely that enhanced interfaces will provide a suite of richer interactions that may explicitly challenge us on this front, rather than defaulting to one-liner prompts, squashed into a HTML text input.
There is of course a whole separate debate to be had as to what it might mean for such a model to make art for itself or other machines, and even if we could realistically recognise it doing so. In the mean time it’s a technology that will likely reveal more about ourselves, how we perceive the world and our emotional relationship to images, perhaps in time taking the the form of industrial-grade, cheaply available art therapy.
That the go-to nomenclature for such technologies is ‘dream’ i.e DeepDream, Dream Studio, Dream Fusion etc, may not be as trivial as it might first appears if in time such software performs a perceptual function similar to actual dreaming, albeit a little more on-demand.
As with dreaming though, the process of AI image generation is generally speaking far more fascinating than any specific output. The most common audience responses usually concern method – ‘how was that done?’ and ‘can I do it too?’.
Very few AI images hold our attention in a meaningful way except perhaps those with a particular satirical resonance (see Jeflon Zuckergates) which capitalise on Stable Diffusions dazzling capacity to seamlessly blend between numerous semantic concepts.

Reading through the pages of community generated add-ons already reveals the pathology of its current userbase to some extent – a blend of fantasy castles, cyberpunk streets, celebrity portraits, and of course endless, endless waifus. Beyond meme soup of X in the style of Y, lies a whole alphabet of image-based psychoanalysis.
Indeed using Stable Diffusion has gradually unpicked and reassembled my own visual inclinations, distilling a mix of 70’s conceptual sculpture, waste materials, geology and architectural formalism. For all the discussion about what it will mean for artists to have their work encoded into such models, it’s also more than a little humbling to have an AI suggest that your images resemble an artist you thought you weren’t obviously ripping off.


What Dreams May Come
While it’s astonishing that models like Stable Diffusion are capable of such outputs, they are still hyper-specialised only within a single domain, the question lingers about what happens as they start to become even slightly more general or perhaps even why they aren’t already.
This concern is at the centre of Stanislas Dehaenes highly approachable ‘How We Learn: The New Science of Education and the Brain’, in which he compares the limit of current machine learning to the multi-layered, multi-sensory and social nature of human learning and it’s surprising adaptability and robustness.
More recently the multi-author paper Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution is in essence a challenge to the wider AI research community to lean more fully into the study of Neuroscience and so-called ‘NeuroAI’, and to explore biological models that might radically improve the environmental interactions, flexibility and energy efficiency of AI. Certainly many in the field are betting on neuro-biologically inspired research to further reveal how to better design software intelligences while possibly helping us understand our own brains in the process.

Among the authors is Jeff Hawkins, co-founder of Numenta (and formely co-founder of Palm Computing, originators of the PalmPilot) and author of the recent A Thousand Brains: A New Theory of Intelligence. The book is a cogent articulation of why AI needs neuroscience, based on two decades of research into the neocortex and it’s seemingly all-purpose role in high-level cognitive tasks – such as language. Emerging from this work are new theories of the organisation of the neocortex based on cortical columns and ‘frames of reference’, that might yet be one of the building blocks of neuro-inspired computational models.
A key observation is that intelligence in biological systems is at least one or two orders of magnitude more efficient that current software approaches – implying there is still massive headroom in realising ever more powerful AI systems. It’s somewhat surprising perhaps that the artificial intelligence community maintains any distance from neuroscientific enquiry when so many of the active topics as, attention, episodic memory and of course neural networks themselves, are direct biological in origin.
Of particular value are ‘sparse’ networks, or ones with a minimal amount of connections is already appearing to have significant performance in real world applications, with a claimed improvement of 100x improvement in the “Performance Acceleration in Deep Learning Networks”. As they write in their whitepaper: “How is the brain so intelligent with such amazing efficiency? One reason is that most of the neocortex is sparse. It stores and processes information in the context of extremely sparse neural activity and sparse connectivity.”

Although this is only a single example, it demonstrates there is still plenty of room for step-change improvements in artificial intelligence. It’s not just that models may become computationally more dazzling, but more nimble, easier to train, run and embed.
Altogether it feels like we’re at an inflection point. On one hand Stable Diffusion demonstrates that open-sourcing AI models can ignite creativity around them – especially as media technologies – far more rapidly than the initial attempts to commercialise them as AI-as-a-service or a via APIs. Simultaneously, the underlying architectures are still a space of wild invention and likely to become ever more ‘untameable’. Now we’ve established Doom can indeed run on your pregnancy test or potato-powered TI-84 calculator, or even ATM, perhaps the next question may be will they run Stable Diffusion and what happens when they do?